2. Das OSI-Modell
Das ISO/OSI-Referenzmodell (englisch Open Systems Interconnection model) ist ein Referenzmodell für Netzwerkprotokolle als Schichtenarchitektur. Es wird seit 1983 von der International Telecommunication Union (ITU) und seit 1984 auch von der International Organization for Standardization (ISO) als Standard veröffentlicht. Seine Entwicklung begann im Jahr 1977.
Zweck des OSI-Modells ist es, Kommunikation über unterschiedlichste technische Systeme hinweg zu beschreiben und die Weiterentwicklung zu begünstigen. Dazu definiert dieses Modell sieben aufeinanderfolgende Schichten (engl. layers) mit jeweils eng begrenzten Aufgaben. In der gleichen Schicht mit klaren Schnittstellen definierte Netzwerkprotokolle sind einfach untereinander austauschbar, selbst wenn sie wie das Internet Protocol eine zentrale Funktion haben.
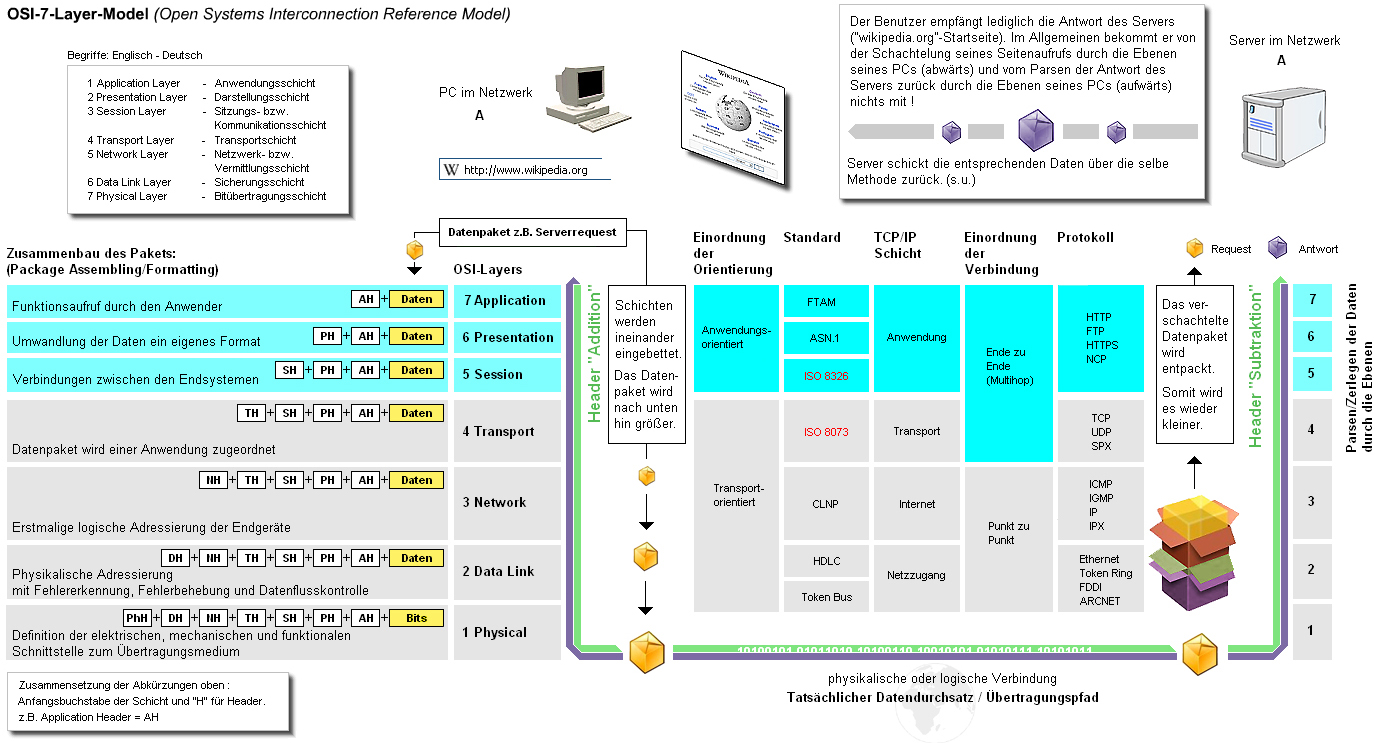
2.1 Protokoll-Schema
2.2 Die 7 Schichten
Schicht 1 – Bitübertragungsschicht (Physical Layer)
Die Bitübertragungsschicht definiert die elektrische, mechanische und funktionale Schnittstelle zum Übertragungsmedium. Die Protokolle dieser Schicht unterscheiden sich nur nach dem eingesetzten Übertragungsmedium und -verfahren.
Die Bitübertragungsschicht (engl. Physical Layer) ist die unterste Schicht. Diese Schicht stellt mechanische, elektrische und weitere funktionale Hilfsmittel zur Verfügung, um physische Verbindungen zu aktivieren bzw. zu deaktivieren, sie aufrechtzuerhalten und Bits darüber zu übertragen. Das können zum Beispiel elektrische Signale, optische Signale (Lichtleiter, Laser), elektromagnetische Wellen (drahtlose Netze) oder Schall sein. Die dabei verwendeten Verfahren bezeichnet man als übertragungstechnische Verfahren. Geräte und Netzkomponenten, die der Bitübertragungsschicht zugeordnet werden, sind zum Beispiel die Antenne und der Verstärker, Stecker und Buchse für das Netzwerkkabel, der Repeater, der Hub, das T-Stück und der Abschlusswiderstand (Terminator).
Auf der Bitübertragungsschicht wird die digitale Bitübertragung auf einer leitungsgebundenen oder leitungslosen Übertragungsstrecke bewerkstelligt. Die gemeinsame Nutzung eines Übertragungsmediums kann auf dieser Schicht durch statisches Multiplexen oder dynamisches Multiplexen erfolgen. Dies erfordert neben den Spezifikationen bestimmter Übertragungsmedien (zum Beispiel Kupferkabel, Lichtwellenleiter, Stromnetz) und der Definition von Steckverbindungen noch weitere Elemente.
Darüber hinaus muss auf dieser Ebene gelöst werden, auf welche Art und Weise ein einzelnes Bit übertragen werden soll: In Rechnernetzen werden Informationen in Form von Bit- oder Symbolfolgen übertragen. In Kupferkabeln und bei Funkübertragung sind modulierte, hochfrequente, elektromagnetische Wellen die Informationsträger, in Lichtwellenleitern Lichtwellen einer oder mehrerer bestimmter Wellenlängen. Die Informationsträger können abhängig von der Modulation nicht nur zwei Zustände für null und eins annehmen, sondern gegebenenfalls weitaus mehr. Für jede Übertragungsart muss daher eine Codierung festgelegt werden. Das geschieht mit Hilfe der Spezifikation der Bitübertragungsschicht eines Netzes.
Hardware auf dieser Schicht: Repeater, Hubs, Leitungen, Stecker etc.
Protokolle und Normen: V.24, V.28, X.21, RS 232, RS 422, RS 423, RS 499
Schicht 2 – Sicherungsschicht (Data Link Layer)
Die Sicherungsschicht sorgt für eine zuverlässige und funktionierende Verbindung zwischen Endgerät und Übertragungsmedium. Zur Vermeidung von Übertragungsfehlern und Datenverlust enthält diese Schicht Funktionen zur Fehlererkennung, Fehlerbehebung und Datenflusskontrolle. Auf dieser Schicht findet auch die physikalische Adressierung von Datenpaketen statt.
Aufgabe der Sicherungsschicht (engl. Data Link Layer; auch Abschnittssicherungsschicht, Datensicherungsschicht, Verbindungssicherungsschicht, Verbindungsebene, Prozedurebene) ist es, eine zuverlässige, das heisst weitgehend fehlerfreie Übertragung zu gewährleisten und den Zugriff auf das Übertragungsmedium zu regeln. Dazu dient das Aufteilen des Bitdatenstromes in Blöcke – auch als Frames oder Rahmen bezeichnet – und das Hinzufügen von Prüfsummen im Rahmen der Kanalkodierung. So können fehlerhafte Blöcke vom Empfänger erkannt und entweder verworfen oder sogar korrigiert werden; ein erneutes Anfordern verworfener Blöcke sieht diese Schicht aber nicht vor.
Eine «Datenflusskontrolle» ermöglicht es, dass ein Empfänger dynamisch steuert, mit welcher Geschwindigkeit die Gegenseite Blöcke senden darf. Die internationale Ingenieursorganisation IEEE sah die Notwendigkeit, für lokale Netze auch den konkurrierenden Zugriff auf ein Übertragungsmedium zu regeln, was im OSI-Modell nicht vorgesehen ist.
Nach IEEE ist Schicht 2 in zwei Unter-Schichten (sub layers) unterteilt: LLC (Logical Link Control, Schicht 2b) und MAC (Media Access Control, Schicht 2a).
Hardware auf dieser Schicht: Bridge, Switch (Multiport-Bridge)
Das Ethernet-Protokoll beschreibt sowohl Schicht 1 als auch Schicht 2, wobei auf dieser als Zugriffskontrolle CSMA/CD zum Einsatz kommt.
Protokolle und Normen, die auf anderen Schicht-2-Protokollen und -Normen aufsetzen: HDLC, SDLC, DDCMP, IEEE 802.2 (LLC), RLC, PDCP, ARP, RARP, STP, Shortest Path Bridging
Protokolle und Normen, die direkt auf Schicht 1 aufsetzen: IEEE 802.11 (WLAN), IEEE 802.4 (Token Bus), IEEE 802.5 (Token Ring), FDDI
Schicht 3 – Vermittlungsschicht (Network Layer)
Die Vermittlungsschicht steuert die zeitliche und logische getrennte Kommunikation zwischen den Endgeräten, unabhängig vom Übertragungsmedium und der Topologie. Auf dieser Schicht erfolgt erstmals die logische Adressierung der Endgeräte. Die Adressierung ist eng mit dem Routing (Wegfindung vom Sender zum Empfänger) verbunden.
Die Vermittlungsschicht (engl. Network Layer; auch Paketebene oder Netzwerkschicht) sorgt bei leitungsorientierten Diensten für das Schalten von Verbindungen und bei paketorientierten Diensten für die Weitervermittlung von Datenpaketen sowie die Stauvermeidung (engl. congestion avoidance). Die Datenübertragung geht in beiden Fällen jeweils über das gesamte Kommunikationsnetz hinweg und schliesst die Wegsuche (Routing) zwischen den Netzwerkknoten ein. Da nicht immer eine direkte Kommunikation zwischen Absender und Ziel möglich ist, müssen Pakete von Knoten, die auf dem Weg liegen, weitergeleitet werden. Weitervermittelte Pakete gelangen nicht in die höheren Schichten, sondern werden mit einem neuen Zwischenziel versehen und an den nächsten Knoten gesendet.
Zu den wichtigsten Aufgaben der Vermittlungsschicht zählt das Bereitstellen netzwerkübergreifender Adressen, das Routing bzw. der Aufbau und die Aktualisierung von Routingtabellen und die Fragmentierung von Datenpaketen. Aber auch die Aushandlung und Sicherstellung einer gewissen Dienstgüte fällt in den Aufgabenbereich der Vermittlungsschicht.
Neben dem Internet Protocol zählen auch die NSAP-Adressen zu dieser Schicht. Da ein Kommunikationsnetz aus mehreren Teilnetzen unterschiedlicher Übertragungsmedien und -protokolle bestehen kann, sind in dieser Schicht auch die Umsetzungsfunktionen angesiedelt, die für eine Weiterleitung zwischen den Teilnetzen notwendig sind.
Hardware auf dieser Schicht: Router, Layer-3-Switch (BRouter)
Protokolle und Normen: X.25, ISO 8208, ISO 8473 (CLNP), ISO 9542 (ESIS), IP, IPsec, ICMP
Schicht 4 – Transportschicht (Transport Layer)
Die Transportschicht ist das Bindeglied zwischen den transportorientierten und anwendungsorientierten Schichten. Hier werden die Datenpakete einer Anwendung zugeordnet.
Zu den Aufgaben der Transportschicht (engl. Transport Layer; auch Ende-zu-Ende-Kontrolle, Transport-Kontrolle) zählt die Segmentierung des Datenstroms, die Stauvermeidung (engl. congestion avoidance) und die Sicherstellung einer fehlerfreien Übertragung.
Ein Datensegment ist dabei eine Service Data Unit, die zur Datenkapselung auf der vierten Schicht (Transportschicht) verwendet wird. Es besteht aus Protokollelementen, die Schicht-4-Steuerungsinformationen enthalten. Als Adressierung wird dem Datensegment eine Schicht-4-Adresse vergeben, also ein Port. Das Datensegment wird in der Schicht 3 in ein Datenpaket gekapselt.
Die Transportschicht bietet den anwendungsorientierten Schichten 5 bis 7 einen einheitlichen Zugriff, so dass diese die Eigenschaften des Kommunikationsnetzes nicht zu berücksichtigen brauchen.
Fünf verschiedene Dienstklassen unterschiedlicher Güte sind in Schicht 4 definiert und können von den oberen Schichten benutzt werden, vom einfachsten bis zum komfortabelsten Dienst mit Multiplexmechanismen, Fehlersicherungs- und Fehlerbehebungsverfahren.
Protokolle und Normen: ISO 8073/X.224, ISO 8602, TCP, UDP, SCTP, DCCP
Schicht 5 – Sitzungsschicht (Session Layer)
Die Kommunikationsschicht organisiert die Verbindungen zwischen den Endsystemen. Dazu sind Steuerungs- und Kontrollmechanismen für die Verbindung und den Datenaustausch implementiert.
Die Schicht 5 (Steuerung logischer Verbindungen; engl. Session Layer; auch Sitzungsschicht, Kommunikationsschicht, Kommunikationssteuerungsschicht) sorgt für die Prozesskommunikation zwischen zwei Systemen. Hier findet sich unter anderem das Protokoll RPC (Remote Procedure Call). Um Zusammenbrüche der Sitzung und ähnliche Probleme zu beheben, stellt die Sitzungsschicht Dienste für einen organisierten und synchronisierten Datenaustausch zur Verfügung. Zu diesem Zweck werden Wiederaufsetzpunkte, so genannte Fixpunkte (Check Points) eingeführt, an denen die Sitzung nach einem Ausfall einer Transportverbindung wieder synchronisiert werden kann, ohne dass die Übertragung wieder von vorne beginnen muss.
Protokolle und Normen: ISO 8326 / X.215 (Session Service), ISO 8327 / X.225 (Connection-Oriented Session Protocol), ISO 9548 (Connectionless Session Protocol)
Schicht 6 – Darstellungsschicht (Presentation Layer)
Die Darstellungsschicht wandelt die Daten in verschiedene Codecs und Formate. Hier werden die Daten zu oder von der Anwendungsschicht in ein geeignetes Format umgewandelt.
Die Darstellungsschicht (engl. Presentation Layer; auch Datendarstellungsschicht, Datenbereitstellungsebene) setzt die systemabhängige Darstellung der Daten (zum Beispiel ASCII, EBCDIC) in eine unabhängige Form um und ermöglicht somit den syntaktisch korrekten Datenaustausch zwischen unterschiedlichen Systemen. Auch Aufgaben wie die Datenkompression und die Verschlüsselung gehören zur Schicht 6. Die Darstellungsschicht gewährleistet, dass Daten, die von der Anwendungsschicht eines Systems gesendet werden, von der Anwendungsschicht eines anderen Systems gelesen werden können. Falls erforderlich, agiert die Darstellungsschicht als Übersetzer zwischen verschiedenen Datenformaten, indem sie ein für beide Systeme verständliches Datenformat, die ASN.1 (Abstract Syntax Notation One), verwendet.
Protokolle und Normen: ISO 8822 / X.216 (Presentation Service), ISO 8823 / X.226 (Connection-Oriented Presentation Protocol), ISO 9576 (Connectionless Presentation Protocol)
Schicht 7 – Anwendungsschicht (Application Layer)
Dienste, Anwendungen und Netzmanagement. Die Anwendungsschicht stellt Funktionen für die Anwendungen zur Verfügung. Diese Schicht stellt die Verbindung zu den unteren Schichten her. Auf dieser Ebene findet auch die Datenein- und ausgabe statt. Die Anwendungen selbst gehören nicht zur Schicht.
Anwendungen: Webbrowser, E-Mail-Programm, Instant Messaging
2.3 Zusammenfassung
7. Schicht / Anwendung: Funktionen für Anwendungen sowie die Dateneingabe und -ausgabe.
6. Schicht / Darstellung: Umwandlung der systemabhängigen Daten in ein unabhängiges Format.
5. Schicht / Sitzung: Steuerung der Verbindungen und des Datenaustauschs.
4. Schicht / Transport: Zuordnung der Datenpakete zu einer Anwendung.
3. Schicht / Vermittlung: Routing der Datenpakete zum nächsten Knoten.
2. Schicht / Sicherung: Segmentierung der Pakete in Frames und Hinzufügen von Prüfsummen.
1. Schicht / Bitübertragung: Umwandlung der Bits in ein zum Medium passendes Signal und physikalische Übertragung.
Zum Verständnis der Funktionsweise von Protokollen in Schichtenmodelle ist es hilfreich zwischen der Adressierung und der Datenübertragung zu unterscheiden.
| Schichten |
Datenverarbeitung und -übertragung |
Adressierung und Verbindungsaufbau |
Anwendung
OSI-Schicht
5 + 6 + 7 |
HTTP, FTP,
IMAP, SMTP
 |
SMB (Windows)
Samba (Unix/Linux)

NetBIOS (Windows)
|
URL:
www.birdgraphics.ch
hosts / DNS
|
NetBIOS-Name
(Computername)
lmhosts / WINS
|
Übertragung
OSI-Schicht
3 + 4 |
Transport: TCP / UDP (Datenpakete)
Adressierung: IP / ICMP (Adresse)
|
IP-Adresse und TCP/UDP-Port
|
Netzzugang
(physikalisch)
OSI-Schicht
1 + 2 |
NDIS
Treiber
Netzwerkkarte (NIC) |
ARP
MAC-Adresse
Ethernet |
2.4 Einsatz des Modells
Das OSI-Referenzmodell wird oft herangezogen, wenn es um das Design von Netzprotokollen und das Verständnis ihrer Funktionen geht. Auf der Basis dieses Modells sind auch Netzprotokolle entwickelt worden, die fast ausschliesslich von Anbietern der öffentlichen Kommunikationstechnik verwendet wurden. Im privaten und kommerziellen Bereich wird hauptsächlich die TCP/IP-Protokoll-Familie eingesetzt. Das TCP/IP-Referenzmodell ist speziell auf den Zusammenschluss von Netzen (internetworking) zugeschnitten.
Die nach dem OSI-Referenzmodell entwickelten Netzprotokolle haben mit der TCP/IP-Protokollfamilie gemeinsam, dass es sich um hierarchische Modelle handelt. Es gibt aber wesentliche konzeptionelle Unterschiede: OSI legt die Dienste genau fest, die jede Schicht für die nächsthöhere zu erbringen hat. TCP/IP hat kein derart strenges Schichtenkonzept wie OSI. Weder sind die Funktionen der Schichten genau festgelegt noch die Dienste. Es ist erlaubt, dass eine untere Schicht unter Umgehung zwischenliegender Schichten direkt von einer höheren Schicht benutzt wird. TCP/IP ist damit erheblich effizienter als die OSI-Protokolle. Nachteil bei TCP/IP ist, dass es für viele kleine Dienste jeweils ein eigenes Netzprotokoll gibt. OSI hat dagegen für seine Protokolle jeweils einen grossen Leistungsumfang festgelegt, der sehr viele Optionen hat. Nicht jede kommerziell erhältliche OSI-Software hat den vollen Leistungsumfang implementiert. Daher wurden OSI-Profile definiert, die jeweils nur einen bestimmten Satz von Optionen beinhalten. OSI-Software unterschiedlicher Hersteller arbeitet zusammen, wenn dieselben Profile implementiert sind.

